
目次
- 目次
- データ解析ライブラリPandas
- インストール
- データファイルの読み込みと書き込み
- データフレームの作成
- データフレームの情報を取得する
- データの抽出
- データフレームの加工
- Pandasでピボット分析
- 10分で学ぶPandasが初心者にはおすすめ
- 参考資料
- MyEnigma Supporters
データ解析ライブラリPandas
Pandasは、データ解析を簡単に実行するための
Pythonライブラリです。
具体的には、データの読み込みや、
読み込んだデータからの、
目的データの抽出、
データの削除、追加などが
簡単に実行可能になります。
元々は統計解析によく使われる
Rという言語で使用されていた
データフレームという考え方を適応し、
Pythonで使用できるようにしたものらしいです。
インストール
基本的にはpipでインストールできるはずです。
pip install pandas
Windowsでpipでpandasをインストールした時にvcvarsall.batが無いと言われた場合
windowsにおいて、
pipでpandasをインストールしようとした時に、
下記のようなエラーが出ることがあります。
error: Microsoft Visual C++ 9.0 is required (Unable to find vcvarsall.bat)
そんな時は下記の記事の通り、
Mirosoftが提供しているVisual C++ コンパイラをインストールしましょう。
コンパイラはここにあります。
データファイルの読み込みと書き込み
データをファイルから読んだり、
データをファイルに書き込む方法について説明します。
CSVファイルからの読み込み
read_csv関数を使いましょう。
この関数が素晴らしいのがcsvにラベルが付いている場合、
自動的にラベル付けをしてデータをpythonの辞書データとして格納してくれる所です。
例えば、下記のようなCSVファイルをread_csv関数で読み込んだ場合、
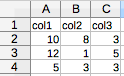
自動で最初の行をデータフレームのラベルとして読み込み、
その列のデータのラベルになります。
あとは、そのラベルを使ってデータにアクセスすることができます。
下記はそのサンプルプログラムです。
import pandas as pd data=pd.read_csv("sampledata.csv") #col3の列のデータを表示 print data["col3"]
この方法でデータを読み、利用することで、
CSVのデータのフォーマットが変わったとしても、
同じラベルが付いているデータは同じコードでアクセスすることができ、
ソフトウェアの再利用性が向上します。
また、ヘッダがついてないCSVファイルを読み込む時は、
下記のように、ヘッダ名を指定することができます。
pd.read_csv( 'foo.txt', names=('a', 'b', 'c') )
CSVファイルへの書き込み
to_csv関数を使いましょう。
データフレームをそのままCSVに変換できます。
#csvデータのエクスポート pd.to_csv("filepatg")
また、上記の方法では
データフレームのインデックスも保存されてしまいますが、
もしインデックスは保存したくない場合は、
下記のようにindex引数をFalseとすればOKです。
#csvデータのエクスポート pd.to_csv("filepatg", index=False)
データフレームの作成
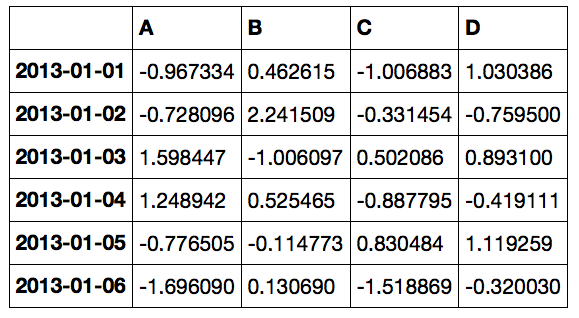
ある時刻毎のデータフレームを作成
data_range関数を使うと、
ある日付から指定した区切り毎の日付のリストを返してくれます。
dates = pd.date_range('20130101', periods=6) df = pd.DataFrame(np.random.randn(6,4), index=dates, columns=list('ABCD')) df
データフレームの情報を取得する
読み取ったデータフレームの情報を表示したい時は、
下記のサンプルコードで使用している変数や関数を使うと便利です。
import seaborn as sns iris = sns.load_dataset("iris") #サンプルデータセット print iris.index print iris.columns print iris.shape iris.info() print iris.describe() print iris.head(5) print iris.tail(10)
index変数
データフレームのデータ番号(行)を表します。

columns変数
データフレームのラベル(列)を表します。

shape変数
データの行と列の数をタプルで返します。
![]()
info関数
データフレームの型などの情報を表示します。

describe関数
データの簡単な統計情報を表示します。
返り値をprintする必要があるので注意が必要です。

head関数
データの頭から指定した行数を表示します。

tail関数
データの末尾から指定した行数を表示します。

データの抽出
pandasのデータフレームは、
色んな方法で一部分を取得することができます。
インデックスを使う
データフレームはindex名で取得できるので非常に便利ですが、
たまに、行列のように
ある列からある列までデータを取得したい時があります。
そんな時はixメンバにアクセスすることで、
行列のインデックスのような形で
部分データを取得することが可能です。
df = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']},
index=[0, 1, 2, 3])
print df
# A B C D
#0 A0 B0 C0 D0
#1 A1 B1 C1 D1
#2 A2 B2 C2 D2
#3 A3 B3 C3 D3
print df.ix[:,1:3] #1-3列を取得
# B C
#0 B0 C0
#1 B1 C1
#2 B2 C2
#3 B3 C3
print df.ix[1:2,:] #1-2行を取得
# A B C D
#1 A1 B1 C1 D1
#2 A2 B2 C2 D2
print df.ix[1:2,1:3] #1-2行と1-3列を取得
# B C
#1 B1 C1
#2 B2 C2
インデックスとカラム名を使ってデータを取得する
atメソッドを使うことで、
インデックスの値とカラム名を指定して、
対応するデータを取得することができます。
import pandas as pd from numpy import random df = pd.DataFrame(random.randn(5,3),columns=list('ABC')) print df # A B C #0 0.256226 -0.261018 -2.246759 #1 1.040020 -0.019676 -0.488064 #2 2.059117 0.080764 0.360490 #3 2.061856 -0.538768 1.015353 #4 0.016484 -0.750428 -0.574846 print df.at[2,"A"] #2.05911699262
条件式を使う
条件文を使って、データを抽出することも簡単です。
フィールドAの値が50以上のデータ行を抽出したい場合は、
下記のようにします。
data.loc[(df["A"] > 50)]
下記のようにすると、条件を満たすB列を抽出できます。
data.loc[(df["A"] > 50), "B"]
isin関数を使う
isin関数を使うと、下記のようなデータフレームにおいて、
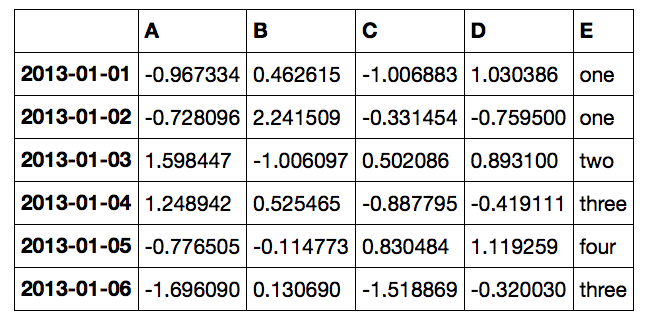
ある行にある指定した要素を含む行を簡単に取得できます。
df[df['E'].isin(['two','four'])]

データフレームの加工
データの欠損値(NaN)の削除
CSVファイルなどを読み込んだ時、
データが無い部分は、欠損値として
NaNが入れられます。
NaNが入った行を削除したい場合は、
dropna関数を使います。
data.dropna() #NaNの入った行を削除する data.dropna(axis=1) #NaNの入った列を削除する data.dropna(subset=["a"]) #aがkeyの列でNaNが入った行を削除する
NaNをある値に置き換えたい時は、fillna関数を使い、
NaNかどうかを判断する行列を取得したい場合は、
isnull関数を使います。
df1.fillna(value=5)
pd.isnull(df1)
データフレームの連結
データフレームを縦や横に連結する場合は、
concat関数を使います
(concatenate: 鎖状に繋げるという意味です)
pd.concat([df1, df2]) # 行方向に連結 pd.concat([df1, df2], axis=1) # 列方向に連結
データフレームのソート
下記のように、
軸でソートしたり、
df.sort_index(axis=0, ascending=False)
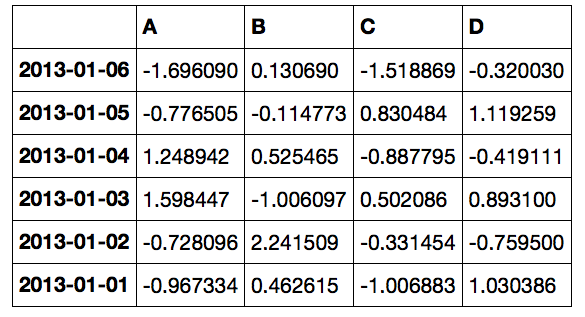
データ列でソートできます。
df.sort_values(by='B')
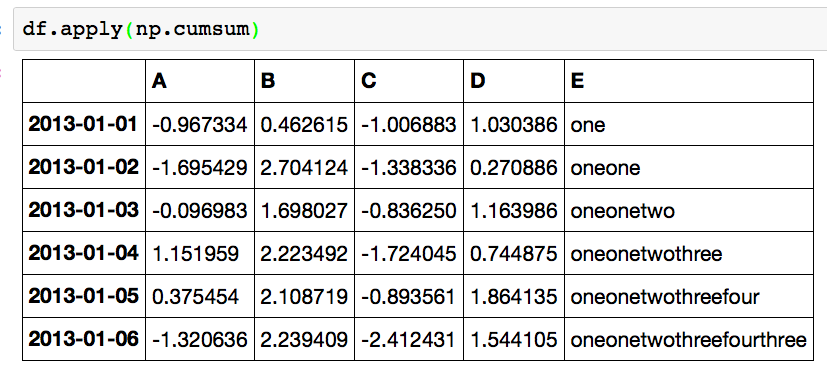
データフレームに関数を適用
データフレームに、ある関数を適用し、
その結果をデータフレームにしたい場合は、
apply関数を使います。
df.apply(np.cumsum)
データフレームの追加
下記のようにappend関数を使うことで、
データフレームを追加することも可能です。
df.append(df.iloc[2], ignore_index=True)

Pandasでピボット分析
Excelなどでよく実施するピボット分析をpandasで実施する場合は、
pivot_table関数を使うとOKです。
カテゴリデータを元に、集計解析などを実施することができます。
10分で学ぶPandasが初心者にはおすすめ
下記の公式ドキュメントにかかれている
10分で学ぶPandasがPandas初心者にはおすすめです。
参考資料
shower.human.waseda.ac.jp/~asaitaku/toolsManual/_sources/python/pandas/tips.txt
Web Analytics or Die » Blog Archive » Pythonデータ解析ライブラリpandasと遊ぶ:クロス集計~検定・残差分析まで
MyEnigma Supporters
もしこの記事が参考になり、
ブログをサポートしたいと思われた方は、
こちらからよろしくお願いします。